Fachlicher Hintergrund
Ein Code ist eine Vorschrift, die eindeutig die Zeichen eines Zeichenvorrats (Urbildmenge) den Zeichen eines anderen Zeichenvorrats (Bildmenge) zuordnet. Zeichen können hierbei Signale oder Symbole sein. Der Zeichenvorrat, auch Alphabet genannt, ist die Menge der zulässigen Zeichen.
Beispiele für Alphabete:
| {A, B, C, …, Y, Z} | gewöhnliches Alphabet |
| {0,1, 2,…, 8, 9} | Dezimalziffern |
| alphanumerischer Zeichenvorrat | Alphabet, das die Buchstaben des gewöhnlichen Alphabets und die Ziffern 0 bis 9 enthält. |
| Zeichensatz des ASCII-Codes | |
| { ∙ , −, Pause} | Zeichen des Morse-Codes |
| {0, 1} | binäres Alphabet |
| ... |
- KFZ-Kennzeichen
- Strichcode auf Verpackungen von Waren (EAN: European Article Number)
- ISBN-Code bei Büchern
- Morsecode
- ASCII-Code
- Flaggencode
- Fliegeralphabet
- …
Je nachdem, welchem Zweck eine Codierung dient, findet man in der Literatur unterschiedliche Begriffe für die codierte Information. Dient die Codierung dem Zweck der Speicherung oder Berechnung, spricht man von Daten.
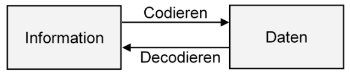
Dient die Codierung dem Zweck der Übertragung von Informationen, wird der Begriff Nachricht verwendet. In diesem Fall kommt, wie in der folgenden Abbildung dargestellt, der Übertragungskanal hinzu.

Die Übertragung kann ggf. verschlüsselt erfolgen (vgl. dazu 3.1.1.4 Informationsgesellschaft und Datensicherheit), worauf hier jedoch nicht eingegangen wird. Der Zweck der Codierung für Datenkompressionen wird im darauf folgenden Schuljahr behandelt (3.2.1.1 Daten und Codierung, IMP9).
Hinweis: Die Begriffe Codieren und Verschlüsseln bzw. Decodieren und Entschlüsseln sollten nicht synonym verwendet werden. In der Codierungstheorie werden ausschließlich die Begriffe Codieren und Decodieren verwendet.
Im weiteren Verlauf wird nicht immer zwischen Daten und Nachricht unterschieden. In diesem Fall wird von der codierten Information gesprochen.
Es stellt sich nun die für diese Einheit zentrale Frage: Kann man erkennen, ob sich bei einer codierten Information Fehler eingeschlichen haben? Und wenn ja, lassen sich diese Fehler auch korrigieren?
Bei der Nachrichtenübertragung ist eine grundsätzliche Idee, dass die Nachricht immer zweimal über den Übertragungskanal geschickt wird und der Empfänger die ankommenden Nachrichten vergleicht. Sind sie nicht identisch, kann der Empfänger die Nachricht noch einmal anfordern. Dass dies nicht die optimale Lösung ist, liegt auf der Hand.
Einfache Verfahren aus der Praxis sind beispielsweise das Bilden einer Quersumme als zusätzliches Prüfbit, Paritätsbits oder Prüfsummenverfahren. Dadurch werden Redundanzen erzeugt, die es ermöglichen, Fehler zu finden oder sie ggf. sogar zu korrigieren. Redundant ist der Teil einer Nachricht, der keine Information enthält.
Unterrichtsverlauf: Herunterladen [odt][408 KB]
Unterrichtsverlauf: Herunterladen [pdf][1 MB]
Weiter zu Wiederholung aus Klasse 7